The NSA/GCHQ Metadata Reassurances Are Breathtakingly Cynical
WHISTLEBLOWING - SURVEILLANCE, 15 Jul 2013
The public is being told that the NSA and GCHQ have ‘only’ been collecting metadata, not content. That’s nothing to be thankful for.
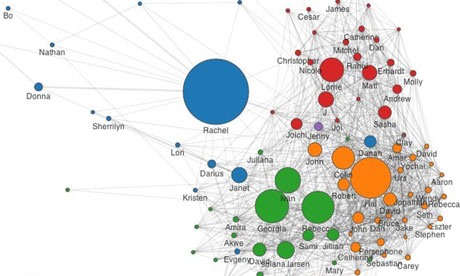
Part of Ethan Zuckerman’s network diagram that highlights the 100 people with whom he communicated most.
Over the past two weeks, I have lost count of the number of officials and government ministers who, when challenged about internet surveillance by GCHQ and the NSA, try to reassure their citizens by saying that the spooks are “only” collecting metadata, not “content”. Only two conclusions are possible from this: either the relevant spokespersons are unbelievably dumb or they are displaying a breathtaking contempt for their citizenry.
In a way, it doesn’t matter which conclusion one draws. The fact is that, as I argued two weeks ago, the metadata is what the spooks want for the simple reason that it’s machine-readable and therefore searchable. It’s what makes comprehensive internet-scale surveillance possible.
Why hasn’t there been greater public outrage about the cynicism of the “just metadata” mantra?
One explanation is that most people imagine that metadata isn’t really very revealing and so they’re not unduly bothered by what NSA and its overseas franchises are doing. If that is indeed what they believe, then my humble suggestion is that they think again.
We already know how detailed an account of an individual’s daily life can be constructed from metadata extracted from a mobile phone. What people may not realise is how informative the metadata extracted from their email logs can be.
In an attempt to illustrate this, MIT researcher Ethan Zuckerman published an extraordinary blog post last Wednesday. Entitled “Me and my metadata”, it explains what happened when two of his students wrote a program to analyse his Gmail account and create from the metadata therein a visualisation of his social network (and of his private life), which he then publishes and discusses in detail. En passant, it’s worth saying that this is a remarkably public-spirited thing to do; not many researchers would have Zuckerman’s courage.
“The largest node in the graph, the person I exchange the most email with, is my wife, Rachel,” he writes. “I find this reassuring, but [the researchers] have told me that people’s romantic partners are rarely their largest node. Because I travel a lot, Rachel and I have a heavily email-dependent relationship, but many people’s romantic relationships are conducted mostly face to face and don’t show up clearly in metadata. But the prominence of Rachel in the graph is, for me, a reminder that one of the reasons we might be concerned about metadata is that it shows strong relationships, whether those relationships are widely known or are secret.”
There’s lots more in this vein. The graph reveals different intensities in his communications with various students, for example, which might reflect their different communication preferences (maybe they prefer face-to-face talks rather than email), or it might indicate that some are getting more supervisory attention than others. And so on. “My point here,” Zuckerman writes, “isn’t to elucidate all the peculiarities of my social network (indeed, analysing these diagrams is a bit like analysing your dreams – fascinating to you, but off-putting to everyone else). It’s to make the case that this metadata paints a very revealing portrait of oneself.”
Spot on. Now do a personal thought-experiment: add to your email metadata the data from your mobile phone and finally your clickstream – the log of every website you’ve visited, ever – all of which are available to the spooks without a warrant. And then ask yourself whether you’re still unconcerned about GCHQ or the NSA or anyone else (for example the French Interior Ministry, when you’re on vacation) scooping up “just” your metadata. Even though – naturally – you’ve nothing to hide. Not even the fact that you sometimes visit, er, sports websites at work? Or that you have a lot of email traffic with someone who doesn’t appear to be either a co-worker or a family member?
How have we stumbled into this Orwellian nightmare? One reason is the naivete/ignorance of legislators who swallowed the spooks’ line that metadata-hoovering was just an updating of older powers to access logs of (analogue) telephone calls. Another is that our political masters didn’t appreciate the capability of digital computing and communications technology. A third is that democratic governments everywhere were so spooked by 9/11 that they were easy meat for bureaucratic empire-builders in the security establishment.
But the most important reason is that all this was set up in secret with inadequate legislative oversight that was further emasculated by lying and deception on the part of spooks and their bosses. And, as any farmer knows, strange things grow in the dark.
Gmail users can see their metadata links at https://immersion.media.mit.edu/
Go to Original – guardian.co.uk
DISCLAIMER: The statements, views and opinions expressed in pieces republished here are solely those of the authors and do not necessarily represent those of TMS. In accordance with title 17 U.S.C. section 107, this material is distributed without profit to those who have expressed a prior interest in receiving the included information for research and educational purposes. TMS has no affiliation whatsoever with the originator of this article nor is TMS endorsed or sponsored by the originator. “GO TO ORIGINAL” links are provided as a convenience to our readers and allow for verification of authenticity. However, as originating pages are often updated by their originating host sites, the versions posted may not match the versions our readers view when clicking the “GO TO ORIGINAL” links. This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available in our efforts to advance understanding of environmental, political, human rights, economic, democracy, scientific, and social justice issues, etc. We believe this constitutes a ‘fair use’ of any such copyrighted material as provided for in section 107 of the US Copyright Law. In accordance with Title 17 U.S.C. Section 107, the material on this site is distributed without profit to those who have expressed a prior interest in receiving the included information for research and educational purposes. For more information go to: http://www.law.cornell.edu/uscode/17/107.shtml. If you wish to use copyrighted material from this site for purposes of your own that go beyond ‘fair use’, you must obtain permission from the copyright owner.
Read more
Click here to go to the current weekly digest or pick another article:
WHISTLEBLOWING - SURVEILLANCE: